# General Imports
import pandas as pd
import matplotlib.pyplot as plt
import plotly.express as px
import numpy as np
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans, DBSCAN
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score
import plotly.io as pio
# Use pio to ensure plotly plots render in Quarto
pio.renderers.default = 'notebook_connected'Unsupervised Learning
Introduction
What is Unsupervised Learning?
In this section, we explore a number of ‘unsupervized learning’ techniques in order to both again build upon our understanding of the data at hand, but also to try and uncover new interesting or hidden relationships within the BBWAA voting data. For some background, unsupervised learning is a branch of machine learning where the algorithms we employ are not given the underlying truth about each point (in our case the voting result - elected, expired, etc.). Because the machine does not have the ground truths, it works to find general underlying trends or patterns in the data1. It is these general patterns and trends that are quite helpful to us as baseball fans, in learning about how BBWWAA voting functions.
Within the realm of unsupervised learning, there are two major tasks that we will utilize in this section. They are clustering and dimensionality reduction. Clustering is the process of grouping data points into distinct groupings based on the underlying features of each point2. By converting the data from a singular dataset into subsets of ‘similar’ groupings, again, based on underlying similarities of each datapoint, we can learn about the relationships between different datapoints, different groupings within our data, and most importantly what drives these similarities and differences. We remember that during this process our computer is not given the truthful group labels for each datapoint, so it relys on the features of the each datapoint for its grouping process.2.
The second process, dimensionality reduction, is used to reduce the number of dimensions our data exists in. While this sounds complicated, if we remember that each column, or feature represents a dimension of the data, this process boils down to reducing the number of columns for the data3. Ideally, we do this in ways that preserve the ‘essense’ of the original data, so that we don’t lose significant useful information that can be used later during the process. Dimensionality reduction offers a few important benefits. First, it makes data visualization of datasets with greater than 3 dimensions possible, by creating the ability to convert the data back into a 2-d or 3-d space. Beyond this however, it can also help make prediction models more accurate on unseen data by reducing correlation between features (multicolinearity) among other benefits3.
Unsupervised Methods Used
In the following Unsupervised Learning section, we will utilize a number of both clustering and dimensionality reduction techniques. We outline the chosen methods below, alongside a brief explanation of how they work:
Clustering
KMeans
KMeans is one of the more popular ‘centroid based’ clustering techniques, meaning the model defines a number of ‘center points’ or centroids to act as the centers of each grouping, and assigns each datapoint to the group belonging to the centroid which it is closest to. As a result, this classifies similar points to the same centroid/group, as they tend to already exist close to one another2. The KMeans clustering algorithm works in the following way.
- A user defined number (k) of centroids are chosen, and the machine randomly places them in the feature space
- Each datapoint in the dataset is classified to the closest centroid, resulting in k groups of datapoints
- The ‘center’ of each group is calculated, and the centroids are moved to these centers
- To calculate the centers, the mean of each group is taken, hence the name KMeans
- Steps 1-3 are repeated until the centers no longer change
The biggest decision when using KMeans is the number of centroids to choose, as this drastically changes the final result of the algorithm. If we know the truthful number of groupings, we can use this number, otherwise it is common practice to run the algorithm with a multitude of different cluster numbers, and choose the final result that results in the most ‘distinct’ clusters. Distinct-ness can be calculated with a few metrics such as the inertia, but in essence we are looking for clusters that are tightly packed to one another, while remaining far away from other clusters4.
DBSCAN
DBSCAN (Density Based Spatial Clustering of Applications with Noise), unlike a centroid based method, is a Density based method meaning it created clusters of the data based on the density of the data at specific points. This is calculated by looking at the number of points which are ‘close’ to any given other point, with closeness being a distance again defined by the user5.
There are generally two important benefits of DBSCAN over K-Means. First, the user does not have to determine the number of clusters. DBSCAN is automatically create its ‘optimal’ number of clusters based on the relative densities of the dataset. The second benefit is that DBSCAN is much less sensetive to outliers. In K-Means, an outlier can drag the cluster out toward it during the means calculations, but DBSCAN is able to classify outliers as ‘noise’, and not assign them to specific clusters5.
Dimensionality Reduction
PCA
Principal Component Analysis, or PCA, is one of the most popular dimensionality reduction techniques, reducing the dimensions of a dataset by projecting the data onto the ‘principal components’ of the data. These principal components are created by using the eigenvectors of the eigenvalues of the data’s covariance matrix3. The user can chose the number of principal components to project onto, which directly determines the number of dimensions the resulting data will exist in after the projection.
The added benefit of PCA is that by projecting onto the principal components, we are minimizing information loss during the reduction. Thus, our resulting data is as informationally similar to our original data as possible, but also much more free from multicolinearity and noise3!
t-SNE
t-distributed Stochastic Neighbor Embedding, or t-SNE, is another method of dimensionality reduction that differs from PCA in its effectiveness with non-linear data. Rather than preserving the maximum variance of the dataset, its primary goal is to map data onto a lower dimension in such a way that points that are close to one another in the original dimensions stay close to one another in the resulting lower dimensions6. Because of this, it is often a great visualization technique for reduced data. The DataCamp page on how t-SNE works offers a great explanation of the major steps within t-SNE, which I have included below:
- t-SNE models a point being selected as a neighbor of another point in both higher and lower dimensions. It starts by calculating a pairwise similarity between all data points in the high-dimensional space using a Gaussian kernel. The points far apart have a lower probability of being picked than the points close together6.
- The algorithm then tries to map higher-dimensional data points onto lower-dimensional space while preserving the pairwise similarities6.
Summary
Now that we are familiar with the underpinnings of supervised learning, including the major techniques and applications of Clustering and Dimensionality Reduction, we can now move forward by applying these techniques to our BBWWAA voting dataset to visualize and explore the underlying relationships of the data!
Code
Dataset Visualization
Principal Component Analysis
All Voting Data Visualizations
2-D Visualization
Before we dive into the clustering methods outlined above, we begin by leveraging PCA for dimensionality reduction to explore our voting data in lower dimensions. We do this because we are fortunate enough to have access to the ground truths for each voting outcome, and can plot with outcome labels to see if clusters are naturally present in the data.
# Load in the data
batter_df = pd.read_csv('../../data/processed-data/batter_df_for_prediction.csv')
# Define the targets, which we will use for coloring plots
str_targets = batter_df.outcome
num_targets = pd.Categorical(batter_df['outcome']).codes
# Filter to only numeric columns, as these are the only plottable ones
numeric_df = batter_df.select_dtypes(include=np.number).drop(columns='votes_pct')When reducing dimensions, it is often a helpful step to standardize and/or scale data beforehand. We do this with scikit-learn’s StandardScaler, which scales all features to a more centered distribution with a standard deviation = 1.
This is done by subtracting the mean of the data from each point and dividing by the original standard deviation
# Scale Data
scaler = StandardScaler()
scaled_data = scaler.fit_transform(numeric_df)After scaling the data, we use PCA to reduce the dataset to 2 dimensions.
# Convert to only 2 Dimensions via PCA
pca = PCA(n_components=2)
pca_df = pca.fit_transform(scaled_data)With this two dimensional dataset, we now plot each data point, with each axis representing an individual principal component.
simple = batter_df[['b_war', 'year_on_ballot']]
pca_df = pd.DataFrame(pca_df, columns=['PC1', 'PC2'])
sns.scatterplot(data=pca_df, x='PC1', y='PC2', hue=str_targets, palette="husl")
plt.title("2D PCA Plot of Ballot Outcomes", fontsize=18)
plt.xlabel('PCA Compnent 1', fontsize=11)
plt.ylabel('PCA Component 2', fontsize=11)Text(0, 0.5, 'PCA Component 2')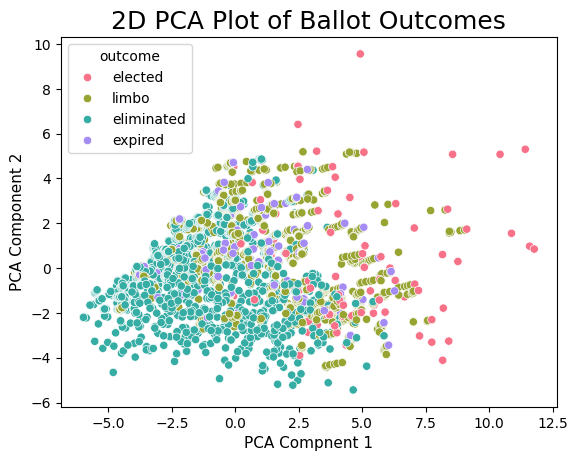
Immediately we see some interesting results! While there is still some overlap between the different outcomes, we still do see a clear pattern where as either PCA Components increase, we see that the outcomes send from elimination, to expiration/limbo to elected. This is a fascinating result because this order can generally be thought of as being increasingly good at baseball. Thus, even within the 2-d PCA data, there are clear visual trends separating HOF players from non-HOF players! Additionally, the fact that we see the different groups start to separate tells us that we have a decent shot at being able to predict whether a player will be elected or not based on their underlying stats.
3D Visualization
As a next step, we undertake the exact same procedure as before, but this time reduce our data to 3 dimensions, to see if the added dimension is able to help separate different clusters.
# Scale Data
scaler = StandardScaler()
scaled_data = scaler.fit_transform(numeric_df)
# Convert to only 2 Dimensions
pca = PCA(n_components=3)
pca_df = pca.fit_transform(scaled_data)# Create a 3D scatter plot
pca_df = pd.DataFrame(pca_df, columns=['PC1', 'PC2', 'PC3'])
# Scatter plot
# Plotly 3D Scatter plot
fig = px.scatter_3d(pca_df, x='PC1', y='PC2', z='PC3', color=str_targets, hover_name = batter_df.player_id,
title='Scatterplot of BBWAA Voting Data along 3 Principal Components',
labels={'X': 'Principal Component 1', 'Y': 'Principal Component 2', 'Z': 'Principal Component 3'})
fig.show()Above, we see that the third dimension does indeed help separate our outcome differences! There still remains some significant overlap between the limbo/expired and eliminated outcomes, but the election outcomes have clearly started to separate themselves, giving us even more hope that predicting outcomes is a reasonable task, especially if we limit to predicting a binary election/non-election outcome.
The other interesting result is we see that there are lots of mini clusters of points each belonging to the same player. You can see this for yourself by hovering the curser over individual points. This occurs becuase the points for all these players are the same other than an added year, plus an update to the last years voting percentage. As a next step, we look to only plot one point per player, plotting them as elected if they were, or else non elected for any other set of outcomes. While this is not feasable as a prediction method given in real time we never know if it is a player’s last year on the ballot, but it is a great exercise in curiosity to see if elected vs non-elected players can be separated visually on the career level.
Career Voting Visualization
# Subset to only one point per player, ensuring we keep the election outcome if it exists.
batter_df = batter_df.sort_values(by='outcome').drop_duplicates(subset=['name'], keep='first')
# Create a new targets column that is binary for if the player was elected
binary_targets = batter_df.outcome == "elected"
# Define the targets, which we will use for coloring plots
str_targets = batter_df.outcome
num_targets = pd.Categorical(batter_df['outcome']).codes
# Filter to only numeric columns, as these are the only plottable ones
numeric_df = batter_df.select_dtypes(include=np.number).drop(columns='votes_pct')
# Print the number of players in the filtered df
print(f"There are {len(numeric_df)} individual players who have been placed on a ballot")
# Scale Data
scaler = StandardScaler()
scaled_data = scaler.fit_transform(numeric_df)
# Convert to only 2 Dimensions
pca = PCA(n_components=3)
pca_df = pca.fit_transform(scaled_data)
# Create a 3D scatter plot
pca_df = pd.DataFrame(pca_df, columns=['PC1', 'PC2', 'PC3'])
# Scatter plot
# Plotly 3D Scatter plot
fig = px.scatter_3d(pca_df, x='PC1', y='PC2', z='PC3', color=binary_targets, hover_name=batter_df.name,
title='Scatterplot of Succesful BBWAA Ballot Elections',
labels={'X': 'Principal Component 1', 'Y': 'Principal Component 2', 'Z': 'Principal Component 3'})
fig.show()There are 781 individual players who have been placed on a ballotConverting the targets to binary values and limiting the data to only one outcome products two pretty stark groupings of points. What is interesting about the data however is that they are not necessarily two ‘distinct’ clusters. There is only one cluster of data from a density standpoint, but it contains a somewhat clean barrier between the two classes. As a result, we are unsure if more tradidional clustering methods will be able to succesfully cluster the data in accordance with the ground truths, but we explore the possibilities below.
t-SNE Visualizations
As a final step before the clustering analysis, we also explore dimensionality reduction via t-SNE. For this we look at the 3 dimensional projection of the data.
# Reduce dimensions with t-sne
tsne = TSNE(n_components=3, random_state=5000, perplexity=30)
tsne_df = tsne.fit_transform(scaled_data)
# Create a 3D scatter plot
tsne_df = pd.DataFrame(tsne_df, columns=['First Dimension', 'Second Dimension', 'Third Dimension'])
# Scatter plot
# Plotly 3D Scatter plot
fig = px.scatter_3d(tsne_df, x='First Dimension', y='Second Dimension', z='Third Dimension', color=str_targets,
title='Interactive 3D Scatter Plot',
labels={'X': 'First Dimension', 'Y': 'Second Dimension', 'Z': 'Third Dimension'})
fig.show()In the above t-SNE plot, we see the algorithm does a pretty good job at keeping points of the same outcome in close proximity to one another. This is a good sign for us, becuase the implication is that back in our higher dimensional space, the data of similar classes is close to one another, leading us once again to believe that predicions of the outcome back in this space is a reasonable exercise.
Clustering Analysis
K-Means
Optimal Known Clusters
Moving into our clustering analysis, we begin by fitting the K-Means algorithm on our dataset with one point per player. Given we know that there are 4 ground truth outcomes, we start by fitting K-Means with 4 clusters.
kmeans = KMeans(n_clusters=4, random_state=5000)
kmeans.fit(scaled_data)
labels = kmeans.labels_
cluster_names = {0: 'Cluster 0', 1: 'Cluster 1', 2: 'Cluster 2', 3: 'Cluster 3'}
labels = pd.Series(labels).map(cluster_names)
fig = px.scatter_3d(pca_df, x='PC1', y='PC2', z='PC3', color=labels,
title='K-Means Results with 4 Clusters',
labels={'X': 'Principal Component 1', 'Y': 'Principal Component 2', 'Z': 'Principal Component 3'})
fig.show()Unsuprisingly, the K-Means algorithm does not fit our data very well. We can see that it pretty equally divides our data into 4 quadrants rather than matching the separations we saw earlier with the ground truths. This is becuase while we saw above the data had some boundries between the outcomes, there were more just boundries than distinct clusters. Without the distinct clustering in the data, K-Means is unable to produce the clusters we are looking for.
Calculating ‘Optimal’ Clusters
One way to choose an optimal number of clusters for K-Means is to plot a metric of choice, in this case intertia, for a varying number of clusters. Then the ‘optimal’ number of clusters becomes the point where the decrease intertia sharply flattens out. This is known as the elbow method. Below, we utilize the elbow method to determine the ‘optimal’ number of clusters as according to K-Means.
scores = []
for n in range(2,10):
kmeans = KMeans(n_clusters=n, random_state=5000)
kmeans.fit(scaled_data)
labels = kmeans.labels_
score = kmeans.inertia_
scores.append(score)
score_df = pd.DataFrame({'n_clusters':range(2,10), 'scores':scores})sns.lineplot(data=score_df, x='n_clusters', y='scores', marker='o')
plt.ylabel('Inertia', fontsize=14)
plt.xlabel('Number of Clusters', fontsize=14)
plt.title('KMeans Silhouette Score Elbow Plot', fontsize=18)Text(0.5, 1.0, 'KMeans Silhouette Score Elbow Plot')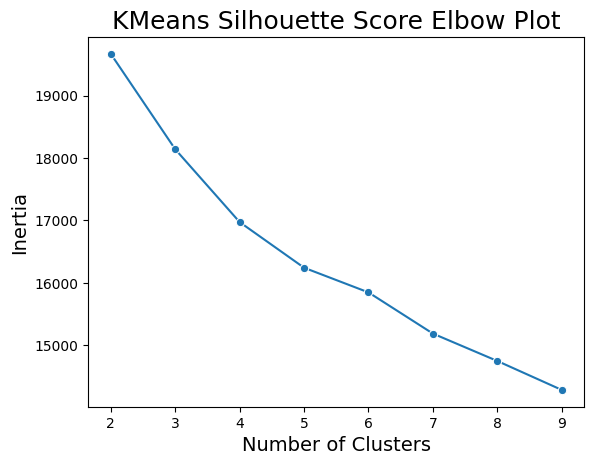
In the elbow chart above, there is not a clear number of clusters to choose as the optimal number. There is some drop off in the decrease in inertia at 5 or 6 clusters, but it is nothing drastic. As such, especially knowing that the true number of outcome classes is 4, we conclude that K-Means does not produce a good fit for out data.
DBSCAN
As a final clustering method to explore, we fit the DBSCAN algorithm to the same dataset as in K-Means, again in 3 dimensions. The results can be seen below:
dbscan = DBSCAN()
dbscan.fit(scaled_data)
labels = dbscan.labels_
fig = px.scatter_3d(pca_df, x='PC1', y='PC2', z='PC3', color=labels,
title='Scatterplot of BBWAA Voting Data, Clustered with DBSCAN',
labels={'X': 'Principal Component 1', 'Y': 'Principal Component 2', 'Z': 'Principal Component 3'})
fig.show()We see above that the DBSCAN method produces even worse results than the K-Means. This makes intuitive sense however, as we see that our data has a fairly uniform density, meaning DBSCAN with converge onto one large cluster (given the lack of varying densities). As we did with K-Means, we once again conclude that DBSCAN does not prodive a good fit to our dataset.
Summary
While the clustering methods did not provide any good fits for our dataset, we did see positive and interesting results with our dimensionality reductions, particularly when paried with ground truth labeling. Because of these positive results, we believe that there is a good possibility we will be able to predict BBWAA voting outcomes with some success! Explanations of these prediction methods, as well as their results can be seen in the next Supervised Learning tab.
References
2.
IBM. What is Clustering.
3.
IBM. Dimensionality Reduction.
4.
IBM. K-means Clustering.
5.
Yenigün, O. DBSCAN Clustering Algorithm Demystified. (2024).
6.
Datacamp. Introduction to t-SNE. (2024).